I'm Jessica.For a few weeks I I wrote a post in response to Ben Recht's Criticism Conformal forecasting to quantify forecast uncertainty.Compared to Ben, I'm more open-minded. conformal prediction and related generalizations like Conformal risk management. Although quantified uncertainty is inherently imperfect as representing the true limits of our knowledge, I still prefer trying to quantify it rather than staying with point estimates. I'm finding value.
If expressions of uncertainty are generally wrong in some way, but still sometimes useful, we should be interested in how people interact with different approaches to quantifying uncertainty. there is. Therefore, I'm interested in seeing how people use the conformal prediction set compared to alternative prediction sets. This is not to say that I think conformal approaches are useless without human interaction (this is the direction of some recent research). conformal decision theory). If we didn't believe that people needed to be involved in so many decision-making processes, I don't think we would have spent the last decade thinking about how people interact with data and models to make decisions.
So today I'd like to discuss what we've learned from a small number of controlled studies that have investigated human use of prediction sets. I'll start with the research I'm most familiar with because it was created in my lab.
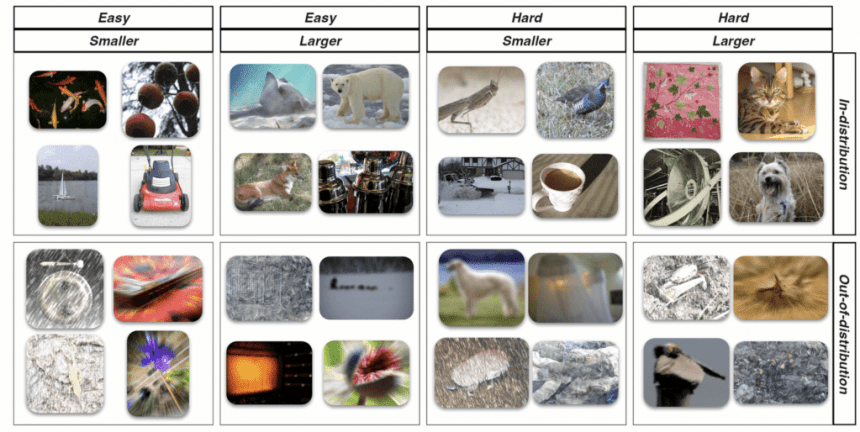
in Evaluating the usefulness of conformal prediction sets for image labeling with AI adviceuses predictive models to study how people make decisions. Specifically, it accesses predictions from pre-trained computer vision models to label images. In keeping with the theme that real-world situations can deviate from expectations, we consider two scenarios. One scenario where the new images come from the same distribution as the images used to train the model, so the model makes very accurate predictions, and the other scenario where the new images deviate from the predictions. Image distribution has ended.
We compared its accuracy and distance between the response and the true label (in the Wordnet hierarchy, which is easily mapped to ImageNet) across four viewing conditions. One had no assistance at all, so we were able to benchmark the accuracy without human assistance against the accuracy of the model in our setup. Humans generally did worse than models in this setting, but there were some cases where humans with AI assistance were able to outperform the models alone.
The other three displays include the model's top predictions using softmax probabilities, the top 10 model predictions using softmax probabilities, and the prediction set generated using split conformal predictions with 95% coverage. , was a model-assisted variation.
The set of predictions we presented was adjusted offline rather than dynamically. Humans make decisions conditioned on model predictions, so we should expect the distribution to change. However, in many cases, the ground truth is not immediately observable and therefore cannot be adaptively adjusted. And even if we do, at a certain point we still have useful prior information and we're probably hovering on the edge of throwing things off track. Therefore, when introducing a new uncertainty quantification into a human decision setting, how does it perform when the setting is as expected and when it is not, i.e. when the guarantees can be misleading? You need to consider whether
Our research partially reaches this point. Ideally, I wanted to test some cases where the stated coverage guarantee for the prediction set was false. However, for the out-of-distribution images we generated, we had to do as much cherry-picking of the stimuli to break the conformal coverage guarantee as much as we broke the top-1 coverage. Coverage decreased slightly, but for the types of perturbations we focused on, it remained fairly high across the set of out-of-distribution instances (compared to 70% for the top 1 and 43% for the top 1). >80%). In the actual set of stimuli tested, coverage was slightly higher for all three, with the largest increase in top 1 coverage (70% compared to 83% for top 10 and 95% for conformal). Below are examples of images that people were classifying (easy and difficult are based on cross-entropy loss considering the model's prediction probability, and small and large refer to the size of the prediction set).

We found that when the test instance is iid, the prediction set does not provide more value than a top 1 or top 10 display, and can be less accurate on average depending on the instance type. However, when test instances are not distributed, accessing the prediction set provides slightly better accuracy than top-k. This is true even when the predicted set of OOD instances becomes very large (the average set size for „easy“ OOD instances defined by the distribution of softmax values was ~17, whereas for „hard“ OOD instances There were 61 items, and we sometimes see sets containing more than 100 items). The average set size of cases in the distribution was approximately 11 for easy instances and 30 for difficult instances.
Based on the differences in coverage across the conditions we investigated, we expect the results to degrade more slowly under unexpected changes, and thus the results may be more informative in situations where conformal prediction is used. It will be expensive.
In designing this experiment in discussion with my co-authors, and thinking further about the value of model-assisted conformal predictions for human decision making, I found that the „bad“ (in the sense of misleading guarantees given) case I've been thinking about it. Spacing may still be better than not quantifying uncertainty.I was recently reading a book by Paul Meal. Clinical and statistical predictionHe contrasts the clinical decisions that doctors make based on intuitive reasoning with the statistical decisions that are based on randomized controlled trials. He notes the distinction between a „justification context“ for the internal sense of probability that leads to a decision such as a diagnosis, and a „validation context“ for collecting the data needed to verify the quality of a prediction. .
Clinicians may be led to make assumptions that turn out to be correct, as in this case. This is because the clinician's brain has a special ability to „notice abnormalities“ and „separate patterns“ that are currently not characteristics of traditional statistics. Technique. Once he has been led to a conjecture of the kind that can be formulated, we can examine him actuarially.
When you think about how prediction intervals affect decision making, whenever you're dealing with humans, you have to wonder what an expression of uncertainty can show and guarantee, and what the value of that expression is to the decision maker. I think there could potentially be differences between them. Quantification with insufficient assurance can still be useful if it changes the context of the discovery in a way that promotes broader thinking or takes the concept of uncertainty seriously there is. This is what I meant when I said in my last post that the meaning of quantifying uncertainty depends on its use. But it's hard to explain exactly how they do this. It's much easier to identify how the calibration breaks.
There are some other the study This looks at the use of conformal prediction sets by humans, but I plan to summarize it in a future post to avoid making this post even longer.
PS There have been some other interesting posts on quantifying uncertainty recently in the CS blogosphere. David Stutz's reply Ben's remarks about conformal prediction, and Design uncertainty quantification for decision making From Aaron Ross.