Eric Van Zvet, Sander Greenland, Guido Invens, Simon Schwab, Steve Goodman and myself write:
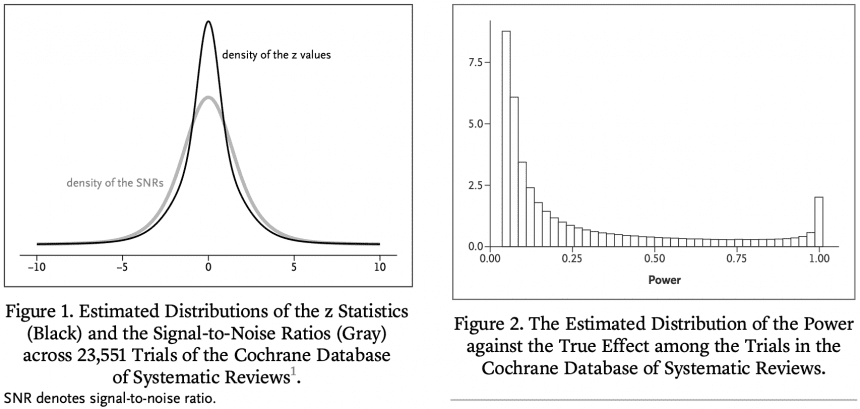
We investigated the main efficacy outcomes of 23,551 randomized clinical trials from the Cochrane Database of Systematic Reviews.
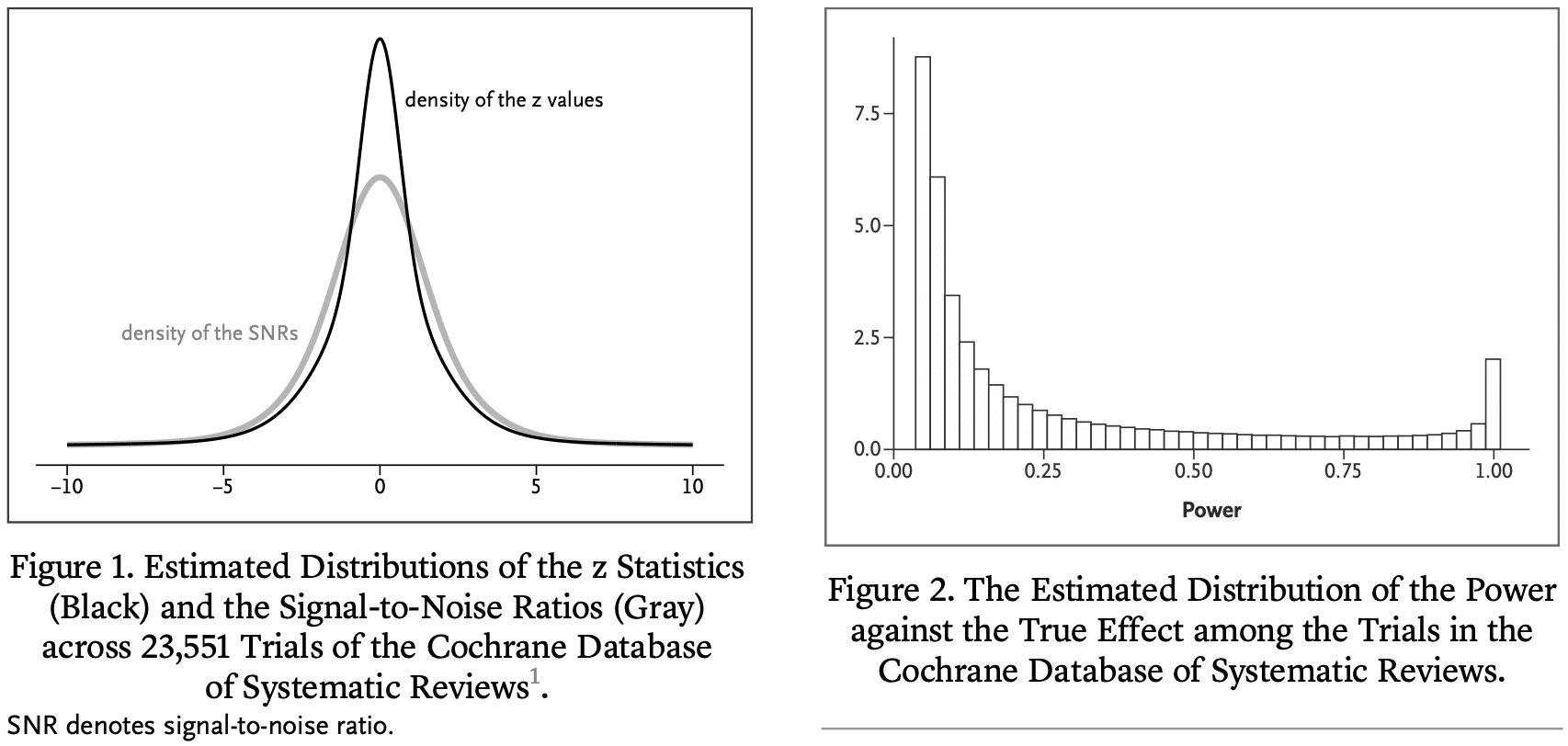
We estimate that in the majority of trials, the statistical power for the true effect is much lower than 80 or 90% of the stated effect size. As a result, „statistically significant“ estimates tend to significantly overestimate the actual treatment effect, „not significant“ results often correspond to important effects, and replication efforts ” are often not achieved and may appear to contradict initial results. To address these issues, we reinterpret P values in terms of the study's reference population that exists or could have existed in the Cochrane database.
This reflects our experience in interpreting P values observed in „typical“ clinical trials in terms of the degree of overestimation of the reported effect, the probability that the sign of the effect is wrong, and the predictive power of the trial. This will lead to a guide.
Such an interpretation can provide further insight into the effect under study and protect medical researchers from naive interpretations of P values and overly optimistic effect sizes. Our results apply beyond the medical field, as many research fields suffer from low power consumption.
This new paper too From Zwet by Lu Tian and Rob Tibshirani:
Evaluation of shrinkage estimates of treatment effects in clinical trials
The primary goal of most clinical trials is to estimate the effectiveness of a treatment compared to a control condition. We define the signal-to-noise ratio (SNR) as the ratio of the SE of the true treatment effect to its estimated value. In a previous publication in this journal, we estimated the distribution of his SNR among clinical trials in the Cochrane Database of Systematic Reviews (CDSR). We found that the SNR was often low. This means that many trials also have low power to detect true effects. Here, we take advantage of the fact that CDSR is a collection of meta-analyses to quantitatively evaluate the results. Some trials that reach statistically significant results show that the usual unbiased estimators are significantly too optimistic and that the associated confidence intervals are not well covered. Previously, we proposed a new shrinkage estimator to deal with this „winner's curse.“ We compare the performance of the shrinkage estimator with the regular unbiased estimator in terms of root mean square error, coverage, and magnitude bias. In terms of statistical significance, we found good performance of the shrinkage estimator both conditionally and unconditionally.
Let me say that last sentence one more time.
In terms of statistical significance, we found good performance of the shrinkage estimator both conditionally and unconditionally.
From a Bayesian perspective, this is not surprising. Bayes is best when averaging the prior distribution, and reasonable when averaging values close to the prior distribution. It is especially reasonable compared to simple unnormalized estimates (like here).
Eric summarizes:
We used a shrinkage estimator to determine how much benefit (on average in the Cochrane database) would be gained. This turns out to be about twice as efficient (in terms of MSE) as the unbiased estimator. This is roughly equivalent to doubling the sample size. We are using a similar methodology to our upcoming paper on single-trial meta-analysis.
People sometimes ask me how I have changed as a statistician over the years. One of the answers I gave was that I was becoming increasingly Bayesian. I started out as a skeptic and had no reservations about Bayesian methods. Then in graduate school I started using Bayesian statistics in applications and realized that it could solve some problems. Still Bayesian when creating BDA and ARM I am sick of And use flat priors whenever possible, or don't talk about priors at all.after that Alex, Sofia, other information points toward a weak prior distribution.In the end, due to the influence of Eric Some try to take advantage of first-hand prior information.At this point I was almost full. lindley.
Compare that to the situation my colleagues and I are in now. My response in 2008 In response to a question from Sanjay Kaul about how to specify a prior distribution for a clinical trial. I wrote:
I think the best prior distributions are based on multilevel models (whether implicit or explicit) based on other similar experiments. Uninformative prior information is fine, but we prefer weaker information to avoid inferences being unduly influenced by highly unrealistic possibilities at the tails of the distribution.
There was nothing exactly wrong with this advice, but I was still leaning toward deinformization.thunder greenland I answered at that time We recommend using first-hand prior information. (And just for fun, here is the discussion From 2014 on a subject where Sander and I disagree. )
Eric concludes:
I think that's really irresponsible. do not have This is because it leverages information from thousands of medical trials conducted over the years. Is that so radical?
That last question reminds me of a 2008 paper. Bayes: Radical, Liberal, or Conservative?
P.S. Also:

you can click through To see the full story.
PPS Click here for details About „From defense to attack“.


